#api with excel
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Why Large Language Models Skip Instructions and How to Address the Issue
New Post has been published on https://thedigitalinsider.com/why-large-language-models-skip-instructions-and-how-to-address-the-issue/
Why Large Language Models Skip Instructions and How to Address the Issue

Large Language Models (LLMs) have rapidly become indispensable Artificial Intelligence (AI) tools, powering applications from chatbots and content creation to coding assistance. Despite their impressive capabilities, a common challenge users face is that these models sometimes skip parts of the instructions they receive, especially when those instructions are lengthy or involve multiple steps. This skipping leads to incomplete or inaccurate outputs, which can cause confusion and erode trust in AI systems. Understanding why LLMs skip instructions and how to address this issue is essential for users who rely on these models for precise and reliable results.
Why Do LLMs Skip Instructions?
LLMs work by reading input text as a sequence of tokens. Tokens are the small pieces into which text is divided. The model processes these tokens one after another, from start to finish. This means that instructions at the beginning of the input tend to get more attention. Later instructions may receive less focus and can be ignored.
This happens because LLMs have a limited attention capacity. Attention is the mechanism models use to decide which input parts are essential when generating responses. When the input is short, attention works well. But attention becomes less as the input gets longer or instructions become complex. This weakens focus on later parts, causing skipping.
In addition, many instructions at once increase complexity. When instructions overlap or conflict, models may become confused. They might try to answer everything but produce vague or contradictory responses. This often results in missing some instructions.
LLMs also share some human-like limits. For example, humans can lose focus when reading long or repetitive texts. Similarly, LLMs can forget later instructions as they process more tokens. This loss of focus is part of the model’s design and limits.
Another reason is how LLMs are trained. They see many examples of simple instructions but fewer complex, multi-step ones. Because of this, models tend to prefer following simpler instructions that are more common in their training data. This bias makes them skip complex instructions. Also, token limits restrict the amount of input the model can process. When inputs exceed these limits, instructions beyond the limit are ignored.
Example: Suppose you give an LLM five instructions in a single prompt. The model may focus mainly on the first two instructions and partially or fully ignore the last three. This directly affects how the model processes tokens sequentially and its attention limitations.
How Well LLMs Manage Sequential Instructions Based on SIFo 2024 Findings
Recent studies have looked carefully at how well LLMs follow several instructions given one after another. One important study is the Sequential Instructions Following (SIFo) Benchmark 2024. This benchmark tests models on tasks that need step-by-step completion of instructions such as text modification, question answering, mathematics, and security rule-following. Each instruction in the sequence depends on the correct completion of the one before it. This approach helps check if the model has followed the whole sequence properly.
The results from SIFo show that even the best LLMs, like GPT-4 and Claude-3, often find it hard to finish all instructions correctly. This is especially true when the instructions are long or complicated. The research points out three main problems that LLMs face with following instructions:
Understanding: Fully grasping what each instruction means.
Reasoning: Linking several instructions together logically to keep the response clear.
Reliable Output: Producing complete and accurate answers, covering all instructions given.
Techniques such as prompt engineering and fine-tuning help improve how well models follow instructions. However, these methods do not completely help with the problem of skipping instructions. Using Reinforcement Learning with Human Feedback (RLHF) further improves the model’s ability to respond appropriately. Still, models have difficulty when instructions require many steps or are very complex.
The study also shows that LLMs work best when instructions are simple, clearly separated, and well-organized. When tasks need long reasoning chains or many steps, model accuracy drops. These findings help suggest better ways to use LLMs well and show the need for building stronger models that can truly follow instructions one after another.
Why LLMs Skip Instructions: Technical Challenges and Practical Considerations
LLMs may skip instructions due to several technical and practical factors rooted in how they process and encode input text.
Limited Attention Span and Information Dilution
LLMs rely on attention mechanisms to assign importance to different input parts. When prompts are concise, the model’s attention is focused and effective. However, as the prompt grows longer or more repetitive, attention becomes diluted, and later tokens or instructions receive less focus, increasing the likelihood that they will be overlooked. This phenomenon, known as information dilution, is especially problematic for instructions that appear late in a prompt. Additionally, models have fixed token limits (e.g., 2048 tokens); any text beyond this threshold is truncated and ignored, causing instructions at the end to be skipped entirely.
Output Complexity and Ambiguity
LLMs can struggle with outputting clear and complete responses when faced with multiple or conflicting instructions. The model may generate partial or vague answers to avoid contradictions or confusion, effectively omitting some instructions. Ambiguity in how instructions are phrased also poses challenges: unclear or imprecise prompts make it difficult for the model to determine the intended actions, raising the risk of skipping or misinterpreting parts of the input.
Prompt Design and Formatting Sensitivity
The structure and phrasing of prompts also play a critical role in instruction-following. Research shows that even small changes in how instructions are written or formatted can significantly impact whether the model adheres to them.
Poorly structured prompts, lacking clear separation, bullet points, or numbering, make it harder for the model to distinguish between steps, increasing the chance of merging or omitting instructions. The model’s internal representation of the prompt is highly sensitive to these variations, which explains why prompt engineering (rephrasing or restructuring prompts) can substantially improve instruction adherence, even if the underlying content remains the same.
How to Fix Instruction Skipping in LLMs
Improving the ability of LLMs to follow instructions accurately is essential for producing reliable and precise results. The following best practices should be considered to minimize instruction skipping and enhance the quality of AI-generated responses:
Tasks Should Be Broken Down into Smaller Parts
Long or multi-step prompts should be divided into smaller, more focused segments. Providing one or two instructions at a time allows the model to maintain better attention and reduces the likelihood of missing any steps.
Example
Instead of combining all instructions into a single prompt, such as, “Summarize the text, list the main points, suggest improvements, and translate it to French,” each instruction should be presented separately or in smaller groups.
Instructions Should Be Formatted Using Numbered Lists or Bullet Points
Organizing instructions with explicit formatting, such as numbered lists or bullet points, helps indicate that each item is an individual task. This clarity increases the chances that the response will address all instructions.
Example
Summarize the following text.
List the main points.
Suggest improvements.
Such formatting provides visual cues that assist the model in recognizing and separating distinct tasks within a prompt.
Instructions Should Be Explicit and Unambiguous
It is essential that instructions clearly state the requirement to complete every step. Ambiguous or vague language should be avoided. The prompt should explicitly indicate that no steps may be skipped.
Example
“Please complete all three tasks below. Skipping any steps is not acceptable.”
Direct statements like this reduce confusion and encourage the model to provide complete answers.
Separate Prompts Should Be Used for High-Stakes or Critical Tasks
Each instruction should be submitted as an individual prompt for tasks where accuracy and completeness are critical. Although this approach may increase interaction time, it significantly improves the likelihood of obtaining complete and precise outputs. This method ensures the model focuses entirely on one task at a time, reducing the risk of missed instructions.
Advanced Strategies to Balance Completeness and Efficiency
Waiting for a response after every single instruction can be time-consuming for users. To improve efficiency while maintaining clarity and reducing skipped instructions, the following advanced prompting techniques may be effective:
Batch Instructions with Clear Formatting and Explicit Labels
Multiple related instructions can be combined into a single prompt, but each should be separated using numbering or headings. The prompt should also instruct the model to respond to all instructions entirely and in order.
Example Prompt
Please complete all the following tasks carefully without skipping any:
Summarize the text below.
List the main points from your summary.
Suggest improvements based on the main points.
Translate the improved text into French.
Chain-of-Thought Style Prompts
Chain-of-thought prompting guides the model to reason through each task step before providing an answer. Encouraging the model to process instructions sequentially within a single response helps ensure that no steps are overlooked, reducing the chance of skipping instructions and improving completeness.
Example Prompt
Read the text below and do the following tasks in order. Show your work clearly:
Summarize the text.
Identify the main points from your summary.
Suggest improvements to the text.
Translate the improved text into French.
Please answer all tasks fully and separately in one reply.
Add Completion Instructions and Reminders
Explicitly remind the model to:
“Answer every task completely.”
“Do not skip any instruction.”
“Separate your answers clearly.”
Such reminders help the model focus on completeness when multiple instructions are combined.
Different Models and Parameter Settings Should Be Tested
Not all LLMs perform equally in following multiple instructions. It is advisable to evaluate various models to identify those that excel in multi-step tasks. Additionally, adjusting parameters such as temperature, maximum tokens, and system prompts may further improve the focus and completeness of responses. Testing these settings helps tailor the model behavior to the specific task requirements.
Fine-Tuning Models and Utilizing External Tools Should Be Considered
Models should be fine-tuned on datasets that include multi-step or sequential instructions to improve their adherence to complex prompts. Techniques such as RLHF can further enhance instruction following.
For advanced use cases, integration of external tools such as APIs, task-specific plugins, or Retrieval Augmented Generation (RAG) systems may provide additional context and control, thereby improving the reliability and accuracy of outputs.
The Bottom Line
LLMs are powerful tools but can skip instructions when prompts are long or complex. This happens because of how they read input and focus their attention. Instructions should be clear, simple, and well-organized for better and more reliable results. Breaking tasks into smaller parts, using lists, and giving direct instructions help models follow steps fully.
Separate prompts can improve accuracy for critical tasks, though they take more time. Moreover, advanced prompt methods like chain-of-thought and clear formatting help balance speed and precision. Furthermore, testing different models and fine-tuning can also improve results. These ideas will help users get consistent, complete answers and make AI tools more useful in real work.
#2024#ADD#ai#AI systems#ai tools#APIs#applications#approach#artificial#Artificial Intelligence#attention#Behavior#benchmark#Bias#Building#challenge#chatbots#claude#coding#complexity#Conflict#content#content creation#data#datasets#Design#efficiency#engineering#excel#focus
1 note
·
View note
Text
Fic data from 2023
Happy new year! This was a big year for me because I got back into reading fanfiction, and boy howdy did I read a lot of it. Over the year I tracked what fics I read got that sweet, sweet data about how much of what I read and when. So now it's time for it to all come together! I put the major stats above the read more line, and below are some other little details about the tags and types of fics. Without further ado, let's get into it!
My goal this year was to read 1000 fics which I realized around June was NOT going to happen. I actually read about 651 fics including re-reads. Not too shabby!
The total words of all the fics I started was 5,196,016 and multiplying by the percent finished (could be >100 for re-reads, or <100 for dnf) I read about 6,214,399 words. So, HOLY BALLS 6.2 MILLION WORDS???? JFC. THATS LIKE 16K EVERY SINGLE DAY. ok i will never again tell myself i didn't read enough this year. Can you imagine if I had hit 1000 fics?
Something else fun about the word count is that the average length was about 1584 words/fic.
My top months by number of fics were February (108 fics), April (88 fics), and March (66 fics). In terms of word count, my top months were February (1.4 million words), January (1.16 million words) and August (804k words).
Keep reading for graphs and data about tags!
Before we get into tags, here's the graphs for the stuff I mentioned earlier. Keep in mind that the first two are about fics I started, not necessarily finished, so the count may vary a bit.
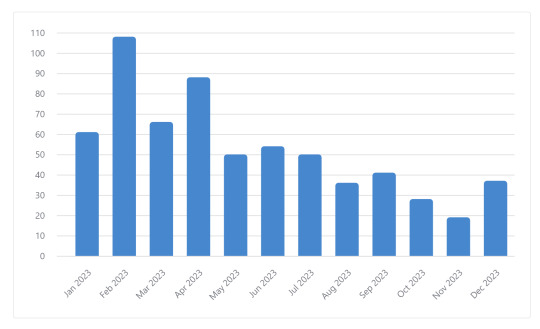
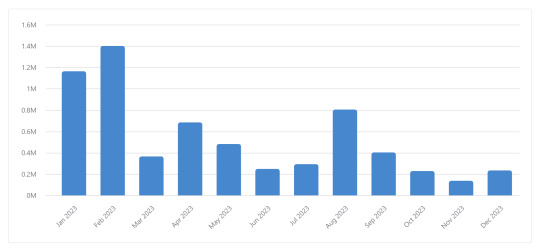
The top three longest fics I read were meet me where the light greets the dark at 115514 words, Subito Sempre at 107053 words, and This Game We Play at 101717 words. Those also happen to be some of my favorite fics of all time.
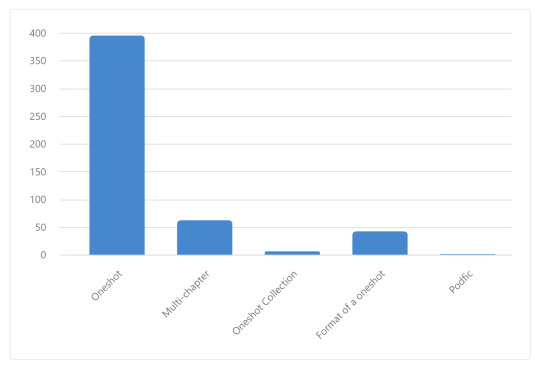
Here's a graph about the length of the fic I read. "Format of a oneshot" is something that may be multiple chapters but was short enough that it could've been one. Idk this database was built on vibes.
I know 54% of the authors! Speaking of, there were 208 distinct authors I read from this year. My top author was JynxedOracle at 33 fics!
These are the fics I re-read most:
OK tag time! Let's start with relationship:
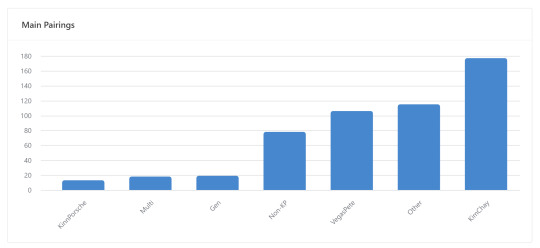
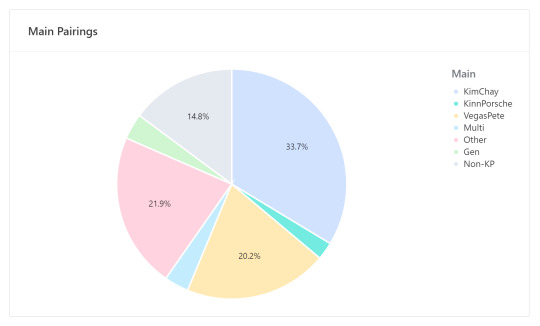
VegasPete almost had it for a while but KimChay will always be my ride or die. Also, if you can't tell, I basically read almost exclusively KinnPorsche The Series fics. For my top fandom outside of KPTS, that would be MCU, and my top non-KP relationship was SpideyPool. My highest rarepair within KPTS will go to my grave or the groupchat. :*)
My highest read additional tag by a WIDE margin (I'm sorry mother) was porn without plot. (Guess that explains why the average words is so low).
I was gonna post the graphs of all my tags but not only are they a mess, I simply refuse to out myself like that this publicly.
On to Warnings and Rating:
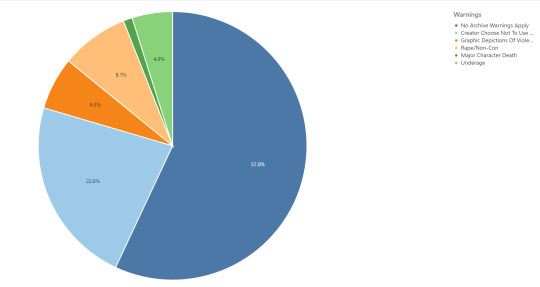
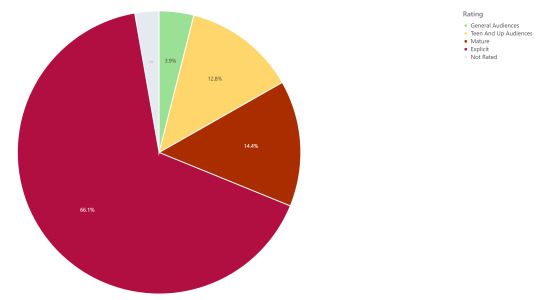
...Don't be ashamed of me, I'm ashamed enough of myself.
Final thing! I met my goodreads goal of 100 books by adding a random book every time I read up to 80k words! My goal for 2024 is to find god and maybe read something other than porn :)
Thanks for reading!

#ao3#ao3 wrapped#data#mm that sexy data#kinnporsche fic#kinnporche the series#kimchay#vegaspete#mcu#spideypool#personal post#fandom#fandom things#fanfiction#i cant express to yall how fun this was#if anyone has tips for how to use excel pls send#i like airtable but the record limit is a killer#im trying to use the ao3 api with python to auto populate excel#it works to an extent but i need help (T T)#fic#ok bye now#this took me way too long to make
13 notes
·
View notes
Text
Dear John, I hope this emails finds you, binds you, ties you to a pole and breaks your fingers to splinters, drags you to a hole until you wake up naked, clawing at the ceiling of your grave
7 notes
·
View notes
Text
Seamless Integration: Dive into the Power of Azure's API Management Toolset.
Elevate your connectivity, security, and efficiency in one robust solution.
2 notes
·
View notes
Text
Automate Nonprofit Payroll: From Excel to Cloud based SaaS with QuickBooks Integration Discover how Satva Solutions transformed nonprofit payroll management by converting Excel to a cloud-based SaaS integrated with QuickBooks, enhancing efficiency and accuracy.
#business#payroll#excel#saas#b2b saas#saas solutions#excel to saas#quickbooks#quickbooks api integration
0 notes
Text
#bulk sms#bulk sms provider#bulk sms service#bulk sms company#bulk sms api#bulk sms gateway#bulk sms delhi#bulk sms pricing#bulk sms software#bulk sms excel software
0 notes
Text
I'm a big fan of extensive reading apps for language learning, and even collaborated on such an app some 10 years ago. It eventually had to be shut down, sadly enough.
Right now, the biggest one in the market is the paywalled LingQ, which is pretty good, but well, requires money.
There's also the OG programs, LWT (Learning With Texts) and FLTR (Foreign Language Text Reader), which are so cumbersome to set up and use that I'm not going to bother with them.
I presently use Vocab Tracker as my daily driver, but I took a spin around GitHub to see what fresh new stuff is being developed. Here's an overview of what I found, as well as VT itself.
(There were a few more, like Aprelendo and TextLingo, which did not have end-user-friendly installations, so I'm not counting them).
Vocab Tracker

++ Available on web ++ 1-5 word-marking hotkeys and instant meanings makes using it a breeze ++ Supports websites
-- Default meaning/translation is not always reliable -- No custom languages -- Ugliest interface by far -- Does not always recognise user-selected phrases -- Virtually unusable on mobile -- Most likely no longer maintained/developed
Lute

++ Supports virtually all languages (custom language support), including Hindi and Sanskrit ++ Per-language, customisable dictionary settings ++ Excellent, customisable hotkey support
-- No instant meaning look-up makes it cumbersome to use, as you have to load an external dictionary for each word -- Docker installation
LinguaCafe

++ Instant meanings thanks to pre-loaded dictionaries ++ Supports ebooks, YouTube, subtitles, and websites ++ Customisable fonts ++ Best interface of the bunch
== Has 7 word learning levels, which may be too many for some
-- Hotkeys are not customisable (yet) and existing ones are a bit cumbersome (0 for known, for eg.) -- No online dictionary look-up other than DeepL, which requires an API key (not an intuitive process) -- No custom languages -- Supports a maximum of 15,000 characters per "chapter", making organising longer texts cumbersome -- Docker installation
Dzelda

++ Supports pdf and epub ++ Available on web
-- Requires confirming meaning for each word to mark that word, making it less efficient to read through -- No custom languages, supports only some Latin-script languages -- No user-customisable dictionaries (has a Google Form to suggest more dictionaries)
#langblr#languages#language learning#language immersion#fltr#lwt#lingq#vocab tracker#language learning apps
459 notes
·
View notes
Text
DXVK Tips and Troubleshooting: Launching The Sims 3 with DXVK
A big thank you to @heldhram for additional information from his recent DXVK/Reshade tutorial! ◀ Depending on how you launch the game to play may affect how DXVK is working.
During my usage and testing of DXVK, I noticed substantial varying of committed and working memory usage and fps rates while monitoring my game with Resource Monitor, especially when launching the game with CCMagic or S3MO compared to launching from TS3W.exe/TS3.exe.
It seems DXVK doesn't work properly - or even at all - when the game is launched with CCM/S3MO instead of TS3W.exe/TS3.exe. I don't know if this is also the case using other launchers from EA/Steam/LD and misc launchers, but it might explain why some players using DXVK don't see any improvement using it.
DXVK injects itself into the game exe, so perhaps using launchers bypasses the injection. From extensive testing, I'm inclined to think this is the case.
Someone recently asked me how do we know DXVK is really working. A very good question! lol. I thought as long as the cache showed up in the bin folder it was working, but that was no guarantee it was injected every single time at startup. Until I saw Heldhram's excellent guide to using DXVK with Reshade DX9, I relied on my gaming instincts and dodgy eyesight to determine if it was. 🤭
Using the environment variable Heldhram referred to in his guide, a DXVK Hud is added to the upper left hand corner of your game screen to show it's injected and working, showing the DXVK version, the graphics card version and driver and fps.

This led me to look further into this and was happy to see that you could add an additional line to the DXVK config file to show this and other relevant information on the HUD such as DXVK version, fps, memory usage, gpu driver and more. So if you want to make sure that DXVK is actually injected, on the config file, add the info starting with:
dxvk.hud =
After '=', add what you want to see. So 'version' (without quotes) shows the DXVK version. dxvk.hud = version

You could just add the fps by adding 'fps' instead of 'version' if you want.

The DXVK Github page lists all the information you could add to the HUD. It accepts a comma-separated list for multiple options:
devinfo: Displays the name of the GPU and the driver version.
fps: Shows the current frame rate.
frametimes: Shows a frame time graph.
submissions: Shows the number of command buffers submitted per frame.
drawcalls: Shows the number of draw calls and render passes per frame.
pipelines: Shows the total number of graphics and compute pipelines.
descriptors: Shows the number of descriptor pools and descriptor sets.
memory: Shows the amount of device memory allocated and used.
allocations: Shows detailed memory chunk suballocation info.
gpuload: Shows estimated GPU load. May be inaccurate.
version: Shows DXVK version.
api: Shows the D3D feature level used by the application.
cs: Shows worker thread statistics.
compiler: Shows shader compiler activity
samplers: Shows the current number of sampler pairs used [D3D9 Only]
ffshaders: Shows the current number of shaders generated from fixed function state [D3D9 Only]
swvp: Shows whether or not the device is running in software vertex processing mode [D3D9 Only]
scale=x: Scales the HUD by a factor of x (e.g. 1.5)
opacity=y: Adjusts the HUD opacity by a factor of y (e.g. 0.5, 1.0 being fully opaque).
Additionally, DXVK_HUD=1 has the same effect as DXVK_HUD=devinfo,fps, and DXVK_HUD=full enables all available HUD elements.
desiree-uk notes: The site is for the latest version of DXVK, so it shows the line typed as 'DXVK_HUD=devinfo,fps' with underscore and no spaces, but this didn't work for me. If it also doesn't work for you, try it in lowercase like this: dxvk.hud = version Make sure there is a space before and after the '=' If adding multiple HUD options, seperate them by a comma such as: dxvk.hud = fps,memory,api,version
The page also shows some other useful information regarding DXVK and it's cache file, it's worth a read. (https://github.com/doitsujin/dxvk)
My config file previously showed the DXVK version but I changed it to only show fps. Whatever it shows, it's telling you DXVK is working! DXVK version:


DXVK FPS:

The HUD is quite noticeable, but it's not too obstructive if you keep the info small. It's only when you enable the full HUD using this line: dxvk.hud = full you'll see it takes up practically half the screen! 😄 Whatever is shown, you can still interact with the screen and sims queue.

So while testing this out I noticed that the HUD wasn't showing up on the screen when launching the game via CCM and S3MO but would always show when clicking TS3W.exe. The results were consistent, with DXVK showing that it was running via TS3W.exe, the commited memory was low and steady, the fps didn't drop and there was no lag or stuttereing. I could spend longer in CAS and in game altogether, longer in my older larger save games and the RAM didn't spike as much when saving the game. Launching via CCM/S3MO, the results were sporadic, very high RAM spikes, stuttering and fps rates jumping up and down. There wasn't much difference from DXVK not being installed at all in my opinion.
You can test this out yourself, first with whatever launcher you use to start your game and then without it, clicking TS3.exe or TS3W.exe, making sure the game is running as admin. See if the HUD shows up or not and keep an eye on the memory usage with Resource Monitor running and you'll see the difference. You can delete the line from the config if you really can't stand the sight of it, but you can be sure DXVK is working when you launch the game straight from it's exe and you see smooth, steady memory usage as you play. Give it a try and add in the comments if it works for you or not and which launcher you use! 😊 Other DXVK information:
Make TS3 Run Smoother with DXVK ◀ - by @criisolate How to Use DXVK with Sims 3 ◀ - guide from @nornities and @desiree-uk
How to run The Sims 3 with DXVK & Reshade (Direct3D 9.0c) ◀ - by @heldhram
DXVK - Github ◀
106 notes
·
View notes
Note
can we hear about the bug that in your opinion is the most important in nature? :3
You have subscribed to DAILY BUG FACTS
🪲
TODAY'S FACT IS
Did you know that the European Honey Bee (Apis mellifera) is the most common honey bee worldwide but is not native to the American continents?
These bees will visit many species of plant in a day making them good general pollinators, but not as effective as a specific pollinator (this is also a reminder that it is important to have plants native to your area to invite native and specialized pollinators).
These honey bees are excellent communicators with each other, speaking both with pheromones and 💃dancing. These communications can be used for defense of the hive, recognizing a member of the colony, directing to pollen, or countless other things.
🪲
Thank you for subscribing to DAILY BUG FACTS

Photo by bramblejungle on iNaturalist
#daily bug facts#bug request#bugblr#hymenoptera#western honey bee#apis mellifera#there's no such thing as one insect that's the most important#all insects are important and work together to stabilize and enrich environments#that being said#native species are better for local environments than introduced species are
52 notes
·
View notes
Text
I miss being able to just use an API with `curl`.
Remember that? Remember how nice that was?
You just typed/pasted the URL, typed/piped any other content, and then it just prompted you to type your password. Done. That's it.
Now you need to log in with a browser, find some obscure settings page with API keys and generate a key. Paternalism demands that since some people insecurely store their password for automatic reuse, no one can ever API with a password.
Fine-grained permissions for the key? Hope you got it right the first time. You don't mind having a blocking decision point sprung on you, do ya? Of course not, you're a champ. Here's some docs to comb through.
That is, if the service actually offers API keys. If it requires OAuth, then haha, did you really think you can just make a key and use it? you fool, you unwashed barbarian simpleton.
No, first you'll need to file this form to register an App, and that will give you two keys, okay, and then you're going to take those keys, and - no, stop, stop trying to use the keys, imbecile - now you're going to write a tiny little program, nothing much, just spin up a web server and open a browser and make several API calls to handle the OAuth flow.
Okay, got all that? Excellent, now just run that program with the two keys you have, switch back to the browser, approve the authorization, and now you have two more keys, ain't that just great? You can tell it's more secure because the number of keys and manual steps is bigger.
And now, finally, you can use all four keys to make that API call you wanted. For now. That second pair of keys might expire later.
20 notes
·
View notes
Text
So around the start of the year, I had some fun ripping down the Blaseball beta API, and put it down when Blaseball died, until I learned Rid in the Solarium was doing a weekly showcase on the various Sunbeam teams in the Beta.
I figured I'd have some fun posting some of the more interesting stuff that could be found in the API. Also a massive thank you to Astrid for archiving the files.
Behold, the dichotomy of excellence:
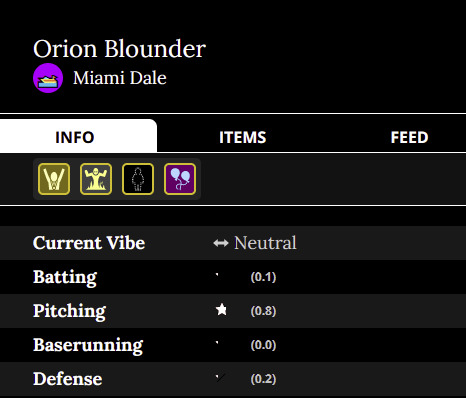
Poor Orion was not having a good time (despite being a Credit to the Team, and the Life of the Party)
On the other end?

Guinevere here wouldn't settle for anything but the best, especially in the Postseason.
Players weren't the other things having a Time(tm) - here was a variant of the Moist Talkers.
Got enough blood?
64 notes
·
View notes
Text
small update; am feeling heaps better and stopped taking ibuprofen last night - no increase in pain so far! however am still super fucking exhausted and a bit of an emotional wreck. the vaginal infection is lessening thanks to the meds but probably won't fully go away until I do another treatment after being done with the antibiotics. I still have to take antibiotics until sunday afternoon.
yesterday I was able to go see HT, which was a huge relief because she is on a 5 week vacation now. some young parts' wishes for the session came true: we cried (a LOT), HT held our hand, and eventually she read us a story. I got to take the book she read to us home for during her vacation, and also our favorite monkey plushie (Apie) gets to stay with us during her vacation.
I decided to take the rest of this whole week off of work to just recover properly. I'll go back to work next week. spoke to my supervisor this morning who gave me the excellent news that I'm getting a 5% raise next year, on top of indexation for inflation. not sure yet what the indexation will be, but even if it's despicably low and only 3%, that still totals an 8% raise. combined with working a few more hours starting january first, I really hope this will give me some financial breathing space again - for savings, for necessities (I fear I might need both a new phone & a new laptop the coming year), and also for some fun every now and then. I can't wait to see what my post-taxes salary will be next year. hopefully taxes won't take away too much, lol.
anyway. that was entirely too much money talk, sorry. just really relieved. gonna lay down again now. hoped to be able to play some stardew but my brain is just so so so sleepy and foggy.
#also been trying to come up with a message to send to my parents at the end of january#to let them know the no contact will continue#but like. woah. that is so fucking hard.#personal
12 notes
·
View notes
Text
Kelby Clark — Language of the Torch (Tentative Power)

Kelby Clark is an LA-by-way-of-Georgia banjo player who blends divergent styles and approaches to forge his own novel direction for the instrument. Over a series of mostly self-released home-spun recordings from the past five or so years, he has honed his approach, expanding the traditions of his point of origin in the American south to include free improvisation and eastern modalities — an alchemy familiar to Sandy Bull, a fellow stretcher of the vocabulary of the banjo and of the concept of “folk” and the traditional. His sparse and appropriately fiery new LP Language of the Torch, available January 10th of next year from Tentative Power, represents a significant milestone in his development of his own science of the banjo, a statement of intent for his artistic practice. It also marks the inaugural 12” LP release from the Baton Rouge, Louisiana label.
Across the seven searching pieces that make up Language of the Torch, Clark constructs a labyrinthine world of music from solo banjo and occasional, subdued harmonium, centered around two longform tracks, “Tennessee Raag Pt.1” and “Tennessee Raag Pt. 3” – there is no part two. These songs help situate the album among its influences, the titles suggesting an imaginational space where Appalachia and India overlap, an interzone frequently visited by practitioners of “American Primitive” music. The intentionally skewed numbering invokes John Fahey, another sometime-raga-obsessive, whose volumes of guitar music are numbered in a non-sensical, non-sequential manner, thumbing the nose at the very concept of numbers and of archiving or cataloging art in volumes. Clark improvises and composes, but on Language of the Torch, the two lengthy “Raags” and the six-minute opening salvo, “Time’s Arc,” feel like the compositions that anchor the shorter, more exploratory tracks that fall between them. Clark’s banjo twangs and drones almost sitar-like during these mesmerizing endurance runs, rough edges flattening over time like water-worn limestone.
In contrast to the patience of these bucolic “Raags,” the shorter tracks on Language of the Torch have an immediacy and attack to them and entertain more old-time flourishes. The concise title cut is perhaps the most traditional, the bends and swoops here feel related to Americana, a brief nod to and deconstruction of familiar forms. Clark is a fluid player, but the percussive nature of the banjo can run counter to fluidity — the most explosive of these improvisations, “Apis,” begins abruptly with an aggressive right-hand trill before it clatters apart and back together again like a musical version of Marcel Duchamp’s Modernist classic “Nude Descending a Staircase, No. 2.” This song is a stand-out and the heaviest example of Clark’s burning vision for the banjo, the “concert instrument” ambition expressed by his forebears in the American Primitive movement.
All traditional forms of music, from Indian Classical to Appalachian Old-Time and permutations between, seem narrowly determined upon a superficial look but reveal their universal nature to those willing to let go of semiotics and sink into their visionary streams. This makes these forms excellent starting points for experimentation, established structures that contain the instructions to build new universes, if one is bold enough to try to read them, and that is what Kelby Clark attempts here with the 5-string banjo and the various traditions from which he draws inspiration. The liner notes for Language of the Torch take the form of a poem by hammered dulcimer player Jen Powers, a fellow traveler on the path of exploding the scope of the traditional. I think the passage below illuminates the process at hand, the conversation between tradition and interpreter:
And maybe now you're wondering whether you are the conjurer or the conjured, and if you really want to know which it is
Josh Moss
#kelby clark#language of the torch#tentative power#josh moss#dusted magazine#albumreview#banjo#sandy bull
7 notes
·
View notes
Text
Programming object lesson of the day:
A couple days ago, one of the side project apps I run (rpthreadtracker.com) went down for no immediately obvious reason. The issue seems to have ended up being that the backend was running on .NET Core 2.2, which the host was no longer supporting, and I had to do a semi-emergency upgrade of all the code to .NET Core 6, a pretty major update that required a lot of syntactic changes and other fixes.
This is, of course, an obvious lesson in keeping an eye on when your code is using a library out of date enough not to be well supported anymore. (I have some thoughts on whether .NET Core 2.2 is old enough to have been dumped like this, but nevertheless I knew it was going out of LTS and could have been more prepared.) But that's all another post.
What really struck me was how valuable it turned out to be that I had already written an integration test suite for this application.
Historically, at basically every job I've worked for and also on most of my side projects, automated testing tends to be the thing most likely to fall by the wayside. When you have 376428648 things you want to do with an application and only a limited number of hours in the day, getting those 376428648 things to work feels very much like the top priority. You test them manually to make sure they work, and think, yeah, I'll get some tests written at some point, if I have time, but this is fine for now.
And to be honest, most of the time it usually is fine! But a robust test suite is one of those things that you don't need... until you suddenly REALLY FUCKING NEED IT.
RPTT is my baby, my longest running side project, the one with the most users, and the one I've put the most work into. So in a fit of side project passion and wanting to Do All The Right Things For Once, I actively wrote a massive amount of tests for it a few years ago. The backend has a full unit test suite that is approaching 100% coverage (which is a dumb metric you shouldn't actually stress about, but again, a post for another day). I also used Postman, an excellently full-featured API client, to write a battery of integration tests which would hit all of the API endpoints in a defined order, storing variables and verifying values as it went to take a mock user all the way through their usage life cycle.
And goddamn was that useful to have now, years later, as I had to fix a metric fuckton of subtle breakage points while porting the app to the updated framework. With one click, I could send the test suite through every endpoint in the backend and get quick feedback on everywhere that it wasn't behaving exactly the way it behaved before the update. And when I was ready to deploy the updated version, I could do so with solid confidence that from the front end's perspective, nothing would be different and everything would slot correctly into place.
I don't say this at all to shame anyone for not prioritizing writing tests - I usually don't, especially on my side projects, and this was a fortuitous outlier. But it was a really good reminder of why tests are a valuable tool in the first place and why they do deserve to be prioritized when it's possible to do so.
#bjk talks#coding#codeblr#programming#progblr#web development#I'm trying to finally get back to streaming this weekend so maybe the upcoming coding stream will be about#setting up one of these integration test suites in postman
78 notes
·
View notes
Text
PSA: Free Software
Reading this may really save your time, privacy, and money! Reblog or share to spread awareness!
Folks often use software that’s expensive and sometimes even inferior because they don’t know there are alternatives. So to those unfamiliar: basically, free and open-source (FOSS) or "libre" software is free to use and anyone can access the original code to make their own version or work on fixing problems.
That does not mean anyone can randomly add a virus and give it to everyone—any respectable libre project has checks in place to make sure changes to the official version are good! Libre software is typically developed by communities who really care about the quality of the software as a goal in itself.
There are libre alternatives to many well-known programs that do everything an average user needs (find out more under the cut!) for free with no DRM, license keys, or subscriptions.
Using libre software when possible is an easy way to fight against and free yourself from corporate greed while actually being more convenient in many cases! If you need an app to do something, perhaps try searching online for things like:
foss [whatever it is]
libre [whatever it is]
open source [whatever it is]
Feel free to recommend more libre software in the tags, replies, comments, or whatever you freaks like to do!
Some Libre Software I Personally Enjoy…
LibreOffice
LibreOffice is an office suite, much like Microsoft Office. It includes equivalents for apps like Word, Excel, and Powerpoint, which can view and edit files created for those apps.
I can't say I've used it much myself yet. I do not personally like using office software except when I have to for school.
OpenShot
OpenShot Video Editor is, as the name suggests, a video editing program. It has industry-standard features like splicing, layering, transitions, and greenscreen.
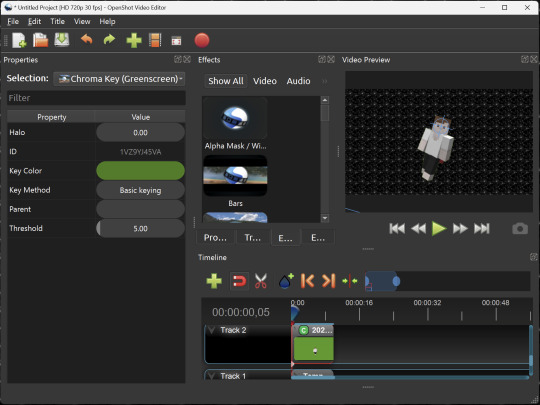
I've only made one video with it so far, but I'm already very happy with it. I had already paid for a video editor (Cyberlink PowerDirector Pro), but I needed to reinstall it and I didn't remember how. Out of desperation, I searched up "FOSS video editor" and I'm so glad I did. There's no launcher, there's no promotion of other apps and asset packs—it's just a video editor with a normal installer.
GIMP
GNU Image Manipulation Program is an image editor, much like Photoshop. Originally created for Linux but also available for Windows and MacOS, it provides plenty of functionality for editing images. It is a bit unintuitive to learn at first, though.
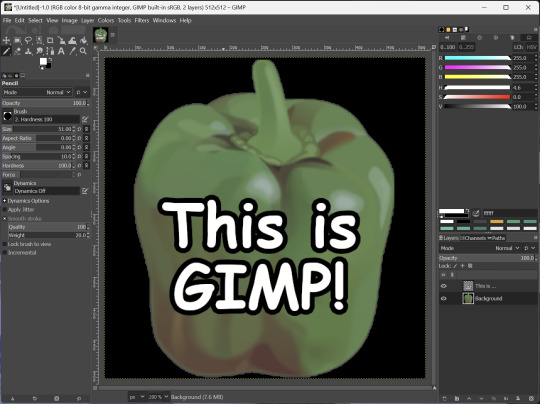
I've used it to create and modify images for years, including logos, really bad traceover art, and Minecraft textures. It doesn't have certain advanced tech like AI paint-in, but it has served my purposes well and it might just work for yours!
(Be sure to go to Windows > Dockable Dialogs > Colors. I have no idea why that's not enabled by default.)
Audacity
Audacity is an audio editing program. It can record, load, splice, and layer audio files and apply effects to them.
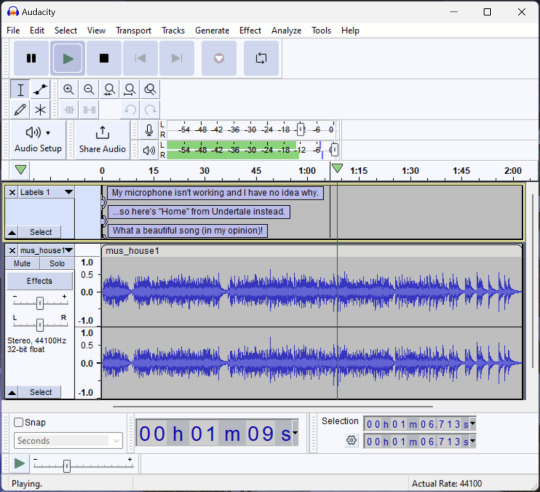
Audacity is another program I've used for a long time. It is not designed to compose music, but it is great for podcasts, simple edits, and loading legacy MS Paint to hear cool noises.
7-Zip
7-Zip is a file manager and archive tool. It supports many archive types including ZIP, RAR, TAR, and its own format, 7Z. It can view and modify the contents of archives, encrypt and decrypt archives, and all that good stuff.
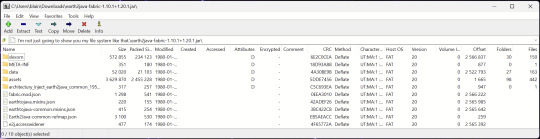
Personally, I use 7-Zip to look inside JAR files for Minecraft reasons. I must admit that its UI is ugly.
Firefox
Firefox is an internet browser, much like Google Chrome, Microsoft Edge, or Safari. While browsers are free, many of them include tracking or other anti-consumer practices. For example, Google plans to release an update to Chromium (the base that most browsers are built from these days) that makes ad blockers less effective by removing the APIs they currently rely on.
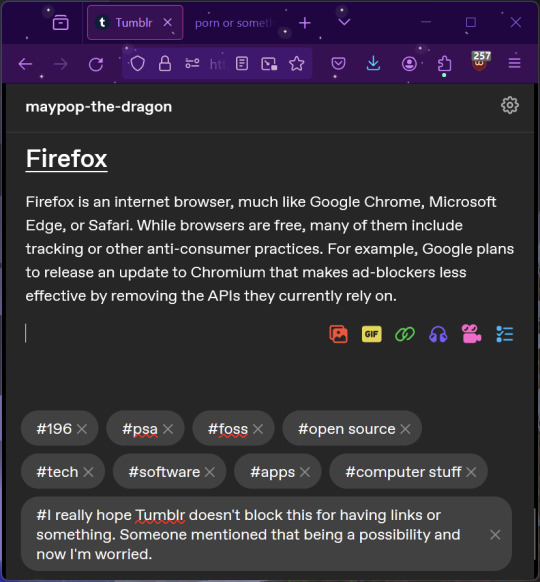
Aside from fighting monopolies, benefits include: support for animated themes (the one in the picture is Purple Night Theme), good ad blockers forever, an (albeit hidden) compact UI option (available on about:config), and a cute fox icon.
uBlock Origin
As far as I know, uBlock Origin is one of the best ad blockers there is.
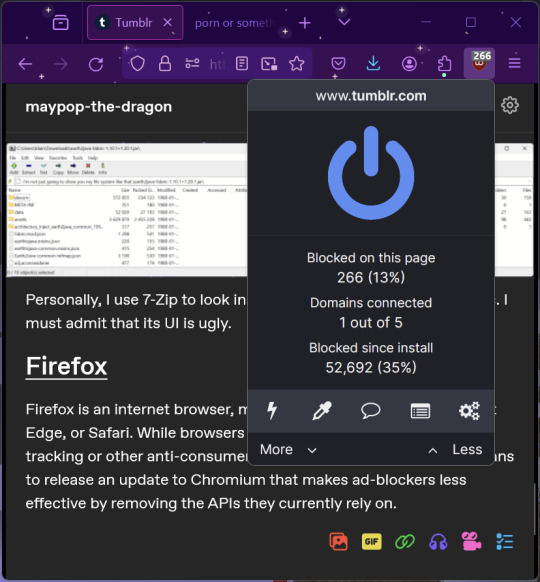
I was on a sketchy website with my brother, and he was using Opera GX's ad blocker. Much of the time when he clicked on anything, it would take us to a random sponsored page. I suggested that he try uBlock Origin, and with uBlock Origin, that didn't happen anymore.
Linux
Linux is a kernel, but the term is often used to refer to operating systems (much like Windows or MacOS) built on it. There are many different Linux-based operating systems (or "distros") to choose from, but apps made for Linux usually work on most popular distros. You can also use many normally Windows-only apps on Linux through compatibility layers like WINE.


I don't have all four of these, so the images are from Wikipedia. I tried to show a variety of Linux distros made for different kinds of users.
If you want to replace your operating system, I recommend being very careful because you can end up breaking things. Many computer manufacturers don't care about supporting Linux, meaning that things may not work (Nvidia graphic cards notoriously have issues on Linux, for example).
Personally, I tried installing Pop!_OS on a laptop, and the sound output mysteriously doesn't work. I may try switching to Arch Linux, since it is extremely customizable and I might be able to experiment until I find a configuration where the audio works.
Many Linux distros offer "Live USB" functionality, which works as both a demo and an installer. You should thoroughly test your distro on a Live USB session before you actually install it to be absolutely sure that everything works. Even if it seems fine, you should probably look into dual-booting with your existing operating system, just in case you need it for some reason.
Happy computering!
#196#psa#foss#open source#tech#software#apps#computer stuff#I really hope Tumblr doesn't block this for having links or something. Someone mentioned that being a possibility and now I'm worried.#please reblog#2024-01-26
47 notes
·
View notes
Note
That thing you did on excel to figure out what songs you haven't listened to jn a while is actually genius now that I'm thinking about it more (and by extension everything you've been working on sjdimsxksk) because i love rediscovering old music sm it makes my day aaaaa
not to toot my own horn but i 100000% agree with you it's crazy the spotify algorithm cld and shld do this the way they have daily mixes etc like a mix of songs tht u havent listened to in like the last 3-6 months etc or idk if it's avail in the api it wld be cool if someone created a website tht wld generate such a playlist but until then i'll be deep in the throes of my excel spreadsheets o7 it's honestly like i've been hearing music i hvent heard since jan-mar n it's crazy i love these songs n it's like the last few months on n off i've been in a music slump i dont want to find totally new music but all the songs i know are boring except WRONG the songs i know are amazing it's just tht spotify algo plays the same ones over n these last few days i've been listening to music till my ears hurt bc yeah the music sounds so good this is the vibe this is how listening to music should be!!!
7 notes
·
View notes